Is Hadoop and Big Data same?
.
Consequently, what is Hadoop and Big Data?
Hadoop is an open-source software framework used for storing and processing Big Data in a distributed manner on large clusters of commodity hardware. Hadoop was developed, based on the paper written by Google on the MapReduce system and it applies concepts of functional programming.
Similarly, how big data and Hadoop are linked? Hadoop is one of the tools designed to handle big data. Hadoop and other software products work to interpret or parse the results of big data searches through specific proprietary algorithms and methods. Hadoop is an open-source program under the Apache license that is maintained by a global community of users.
Herein, is Hadoop only for big data?
Most of the technologies listed above uses Hadoop or other technology to deal completely with Big Data. No, Hadoop is not the only option to implement Big Data. There are others like, Apache Spark.
Why Hadoop is called a big data technology?
Hadoop comes handy when we deal with enormous data. It may not make the process faster, but gives us the capability to use parallel processing capability to handle big data. In short, Hadoop gives us capability to deal with the complexities of high volume, velocity and variety of data (popularly known as 3Vs).
Related Question AnswersIs Hadoop a database?
Hadoop is not a type of database, but rather a software ecosystem that allows for massively parallel computing. It is an enabler of certain types NoSQL distributed databases (such as HBase), which can allow for data to be spread across thousands of servers with little reduction in performance.Is Hadoop a language?
Hadoop is not a programming language. Hadoop [which inclueds Distributed File system[HDFS] and a processing engine [Map reduce/YARN] ] and its ecosystem are set of tools which helps it large data processing. To work on Hadoop, you required basic Java and some basic Computer science understanding.Why is Hadoop used?
Hadoop is used for storing and processing big data. In Hadoop data is stored on inexpensive commodity servers that run as clusters. It is a distributed file system allows concurrent processing and fault tolerance. Hadoop MapReduce programming model is used for faster storage and retrieval of data from its nodes.Why is Hadoop important?
Hadoop is very useful for the big business because it is based on cheap servers so required less cost to store the data and processing the data. Hadoop helps to make a better business decision by providing a history of data and various record of the company, So by using this technology company can improve its business.How do I start Hadoop?
Now let's have a look at the necessary technical skills for learning Hadoop for beginners.- Linux Operating System.
- Programming Skills.
- SQL Knowledge.
- Step 1: Know the purpose of learning Hadoop.
- Step 2: Identify Hadoop components.
- Step 3: Theory – A must to do.
- Step 1: Get your hands dirty.
- Step 2: Become a blog follower.
How is Hadoop used in real life?
Here are some real-life examples of ways other companies are using Hadoop to their advantage.- Analyze life-threatening risks.
- Identify warning signs of security breaches.
- Prevent hardware failure.
- Understand what people think about your company.
- Understand when to sell certain products.
- Find your ideal prospects.
How is data stored in Hadoop?
On a Hadoop cluster, the data within HDFS and the MapReduce system are housed on every machine in the cluster. Data is stored in data blocks on the DataNodes. HDFS replicates those data blocks, usually 128MB in size, and distributes them so they are replicated within multiple nodes across the cluster.How does Hadoop work?
How Hadoop Works? Hadoop does distributed processing for huge data sets across the cluster of commodity servers and works on multiple machines simultaneously. To process any data, the client submits data and program to Hadoop. HDFS stores the data while MapReduce process the data and Yarn divide the tasks.Does Hadoop use SQL?
Using Hive SQL professionals can use Hadoop like a data warehouse. Hive allows professionals with SQL skills to query the data using a SQL like syntax making it an ideal big data tool for integrating Hadoop and other BI tools.Is Hadoop worth learning?
Learning Hadoop will definitely give you a basic understanding about working of other options as well. Moreover, several organizations are using Hadoop for their workload. So there are lot of opportunities for good developers in this domain. Moreover, several organizations are using Hadoop for their workload.Do I need Hadoop?
We need Hadoop mainly to handle very big amount of data in an effective manner when compared with other similar technologies both in cost wise and performance wise. Big Data and Hadoop are the things that are currently in demand in the IT market.Should I learn spark or Hadoop?
No, you don't need to learn Hadoop to learn Spark. Spark was an independent project . But after YARN and Hadoop 2.0, Spark became popular because Spark can run on top of HDFS along with other Hadoop components. Hadoop is a framework in which you write MapReduce job by inheriting Java classes.Does spark need Hadoop?
Yes, Apache Spark can run without Hadoop, standalone, or in the cloud. Spark doesn't need a Hadoop cluster to work. Spark can read and then process data from other file systems as well. HDFS is just one of the file systems that Spark supports.Where is Hadoop used?
Hadoop is in use by an impressive list of companies, including Facebook, LinkedIn, Alibaba, eBay, and Amazon. In short, Hadoop is great for MapReduce data analysis on huge amounts of data.When to Use Hadoop
- For Processing Really BIG Data:
- For Storing a Diverse Set of Data:
- For Parallel Data Processing:
Is Hadoop still used?
Hadoop is not only Hadoop While e folks may be moving away from Hadoop as their choice for big data processing, they will still be using Hadoop in some form or the other.What are the alternatives to Hadoop?
Top Alternatives to Hadoop HDFS- Databricks.
- Cloudera.
- Google BigQuery.
- Hortonworks Data Platform.
- Snowflake.
- Qubole.
- Google Cloud Dataflow.
- Amazon EMR.
How is spark different from Hadoop?
Hadoop is designed to handle batch processing efficiently whereas Spark is designed to handle real-time data efficiently. Hadoop is a high latency computing framework, which does not have an interactive mode whereas Spark is a low latency computing and can process data interactively.What are the components of Hadoop?
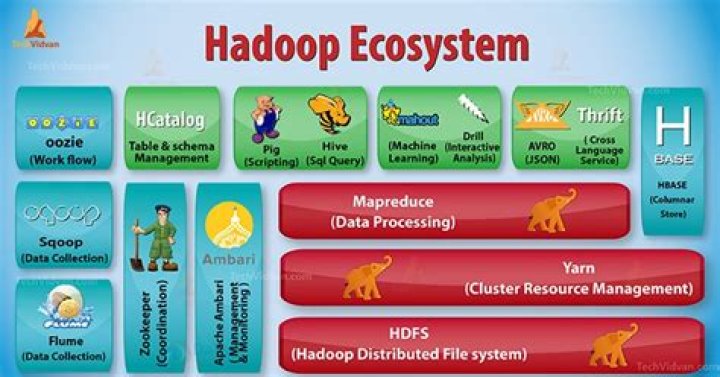
This has become the core components of Hadoop.- Hadoop Distributed File System :
- HDFS is a virtual file system which is scalable, runs on commodity hardware and provides high throughput access to application data.
- Architecture :
- Namenode :
- Datanode :
- 1) Data Integrity :
- 2) Robustness :
- 3) Cluster Rebalancing :