What is data deduplication and why is it important?
.
Also to know is, what is meant by data deduplication?
In computing, data deduplication is a technique for eliminating duplicate copies of repeating data. A related and somewhat synonymous term is single-instance (data) storage. In the deduplication process, unique chunks of data, or byte patterns, are identified and stored during a process of analysis.
Subsequently, question is, what is the most common technique used for finding duplicate blocks data? One of the most common sources of mismatches in database entries is the typographical variations of string data. Therefore, duplicate detection typically relies on string comparison techniques to deal with typographical variations.
Also know, what is data deduplication designed for?
Data deduplication -- often called intelligent compression or single-instance storage -- is a process that eliminates redundant copies of data and reduces storage overhead. Data deduplication techniques ensure that only one unique instance of data is retained on storage media, such as disk, flash or tape.
How do you dedupe data?
Remove duplicate values
- Select the range of cells that has duplicate values you want to remove. Tip: Remove any outlines or subtotals from your data before trying to remove duplicates.
- Click Data > Remove Duplicates, and then Under Columns, check or uncheck the columns where you want to remove the duplicates.
- Click OK.
How does Dedup work?
The data deduplication process works by eliminating redundant data and ensuring that only the first unique instance of any data is actually retained. Subsequent iterations of the data are replaced with a pointer to the original. Data deduplication can operate at the file, block or bit level.Why is data deduplication important?
At its simplest definition, data deduplication refers to a technique for eliminating redundant data in a data set. Reducing the amount of data to transmit across the network can save significant money in terms of storage costs and backup speed — in some cases, savings up to 90%.What is deduplication in Avamar?
Variable-length deduplication is the process used by EMC's Avamar and DataDomain backup devices to condense data by removing common segments of data. Deduplicating these common segments greatly reduces the amount of data needed to be stored on the backup target.What is inline deduplication?
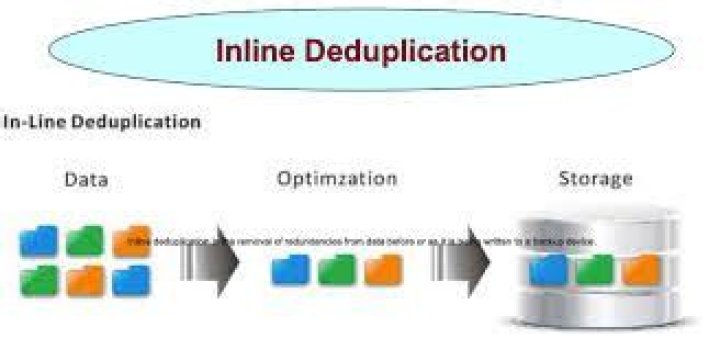
Inline deduplication is the removal of redundancies from data before or as it is being written to a backup device. Inline deduplication reduces the amount of redundant data in an application and the capacity needed for the backup disk targets, in comparison to post-process deduplication.What is the difference between deduplication and compression?
The data protection technologies are similar, but they operate differently. Deduplication looks for redundant pieces of data, while compression uses an algorithm to reduce the bits required to represent data. While deduplication typically works at the block level, compression tends to work at the file level.What does primary storage describe?
A primary storage device is a medium that holds memory for short periods of time while a computer is running. RAM (random access memory) and cache are both examples of a primary storage device. The image shows three different types of storage for computer data.What is duplicate data in database?
Duplicate records in SQL, also known as duplicate rows, are identical rows in an SQL table. This means, for a pair of duplicate records, the values in each column coincide. Usually, we will retrieve duplicate data, when we are joining tables.What is block level deduplication?
Block-level, sometimes called variable block-level deduplication, looks at the data block itself to see if another copy of this block already exists. If so, the second (and subsequent) copies are not stored on the disk/tape, but a link/pointer is created to point to the original copy.Does ReFS support data deduplication?
The ReFS filesystem is commonly used for Virtualization, Backup, and Microsoft Exchange because of its resiliency, real-time tier optimization, faster virtual machine operations, and great scalability. But until recently, ReFS didn't support data deduplication, which was available on NTFS formatted volumes only.Can encrypted data be deduplicated?
Deduplication is a one such storage optimization technique that avoids storing duplicate copies of data. Currently, to ensure security, data stored in cloud as well as other large storage areas are in an encrypted format and one problem with that is, we cannot apply deduplication technique over such an encrypted data.How does Microsoft deduplication work?
Data Deduplication, often called Dedup for short, is a feature that can help reduce the impact of redundant data on storage costs. When enabled, Data Deduplication optimizes free space on a volume by examining the data on the volume by looking for duplicated portions on the volume.What is data deduplication in Windows Server 2012?
Windows Server 2012 data deduplication (often shortened to “dedupe”) is a software-based technology that allows you to most efficiently maximize your data storage space. No additional hardware is needed for the deduplication to take place. In any file system, that technology could save a lot of space.What is deduplication in NetBackup?
With media server deduplication, the NetBackup client software creates the image of backed up files as for a normal backup. The client sends the backup image to a media server, which hosts the plug-in that duplicates the backup data. The storage destination is a Media Server Deduplication Pool.What is data deduplication Server 2016?
As a simple definition, we can tell, data deduplication is an elimination of redundant data in data set and storing only one copy of the same data. It is done by identifying double byte patterns through data analysis, removing double data and replacing it with reference pointed to stored, single piece of data.How does deduplication work in NetBackup?
With NetBackup MSDP client deduplication, clients deduplicate their backup data and then send it directly to the storage server, which writes it to the storage. The network traffic is reduced. Uniqueness of data segments is maintained across all clients – not just for individual client backup data.Which storage technology saves disk space by reducing the size of data?
data deduplication. Data deduplication is a technique used to reduce the amount of storage space an organization needs to save its data. In most organizations, the storage systems contain duplicate copies of many pieces of data.How do I solve a duplicate record in cm90004?
Follow the steps below to mark a transaction as a duplicate:- Go to the Transactions tab, click on the transaction you wish to mark as a duplicate.
- Click on the Edit Details button and then check the box at the bottom of the pop up that states "This is a duplicate".
- Click "I'm Done" to save the changes.