Apache Kafka is a streaming data store that decouples applications producing streaming data (producers) into its data store from applications consuming streaming data (consumers) from its data store. Organizations use Apache Kafka as a data source for applications that continuously analyze and react to streaming data..
Consequently, what is Kafka and how it works?
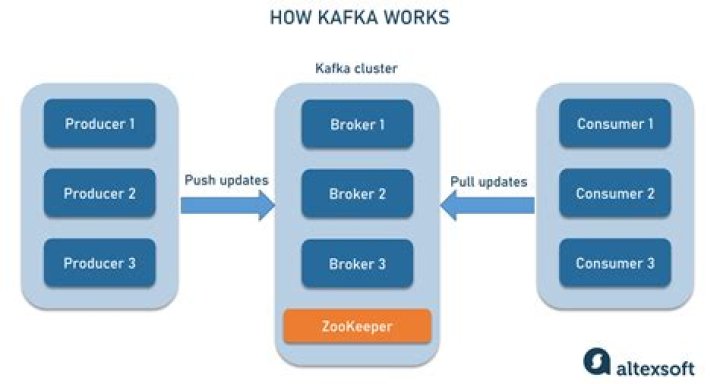
Applications (producers) send messages (records) to a Kafka node (broker) and said messages are processed by other applications called consumers. Said messages get stored in a topic and consumers subscribe to the topic to receive new messages.
Similarly, how much does Kafka cost? As with all things AWS, the pricing is a bit complicated, but a basic Kafka instance will start at $0.21 per hour. You're not likely to just use one instance, so for a somewhat useful setup with three brokers and a good amount of storage and some other fees, you'll quickly pay well over $500 per month.
Similarly one may ask, what is Kafka in simple words?
Kafka is an open source software which provides a framework for storing, reading and analysing streaming data. Being open source means that it is essentially free to use and has a large network of users and developers who contribute towards updates, new features and offering support for new users.
Why is Kafka called Kafka?
Jay Kreps chose to name the software after the author Franz Kafka because it is "a system optimized for writing", and he liked Kafka's work.
Related Question Answers
What are the advantages of Kafka?
Advantages of Kafka Also, able to support message throughput of thousands of messages per second. It is capable of handling these messages with the very low latency of the range of milliseconds, demanded by most of the new use cases. One of the best advantages is Fault Tolerance.Is Kafka a database?
Let's explore a contentious question: is Kafka a database? In some ways, yes: it writes everything to disk, and it replicates data across several machines to ensure durability. In other ways, no: it has no data model, no indexes, no way of querying data except by subscribing to the messages in a topic.Why should I use Kafka?
Kafka is used for real-time streams of data, to collect big data, or to do real time analysis (or both). Kafka is used with in-memory microservices to provide durability and it can be used to feed events to CEP (complex event streaming systems) and IoT/IFTTT-style automation systems.Why is Kafka so fast?
Although this approach makes them fast, the cost of RAM is much more than disk. Such systems are usually costlier to run when you have 100s of GBPS data flowing through the system. Kafka relies on the filesystem for the storage and caching. Modern operating systems allocate most of their free memory to disk-caching.How do I connect to Kafka?
Approach - Install a Kafka server instance locally for evaluation purposes.
- Run the Kafka server and create a new topic.
- Configure the local Atom with the Kafka client libraries.
- Create an AtomSphere integration process to publish messages to the Kafka topic via Groovy custom scripting.
Where is Kafka data stored?
Recap - Data in Kafka is stored in topics.
- Topics are partitioned.
- Each partition is further divided into segments.
- Each segment has a log file to store the actual message and an index file to store the position of the messages in the log file.
Why Kafka is needed?
Kafka is a distributed streaming platform that is used publish and subscribe to streams of records. Kafka gets used for fault tolerant storage. Kafka replicates topic log partitions to multiple servers. Kafka is designed to allow your apps to process records as they occur.Can we use Kafka without zookeeper?
As explained by others, Kafka (even in most recent version) will not work without Zookeeper. Kafka uses Zookeeper for the following: Electing a controller. The controller is one of the brokers and is responsible for maintaining the leader/follower relationship for all the partitions.What does ZooKeeper do for Kafka?
Kafka Architecture: Topics, Producers and Consumers Kafka uses ZooKeeper to manage the cluster. ZooKeeper is used to coordinate the brokers/cluster topology. ZooKeeper is a consistent file system for configuration information. ZooKeeper gets used for leadership election for Broker Topic Partition Leaders.How does Kafka internally work?
Kafka wraps compressed messages together Producers sending compressed messages will compress the batch together and send it as the payload of a wrapped message. And as before, the data on disk is exactly the same as what the broker receives from the producer over the network and sends to its consumers.Is Kafka a data lake?
Kafka provides a robust, reliable and highly scalable solution for processing and queueing streaming data, and is probably the most common building block used in streaming architectures. In the next part of this article, we'll explain why the answer to that question, in most cases, is to build a data lake.How do Kafka brokers communicate?
If you wish to send a message you send it to a specific topic and if you wish to read a message you read it from a specific topic. A consumer pulls messages off of a Kafka topic while producers push messages into a Kafka topic. Each node in the cluster is called a Kafka broker.How do I replay a Kafka message?
Yes, You can replay message. As Consumer have a control over resetting the offset. You can start reading messages from the beginning or if you know any existing offset value you can read it from there as well. Once the message is committed it will be in there in topic until its retention period is over.Does Kafka write to disk?
1 Answer. Kafka always writes directly to disk, but remember one thing the I/O operations are really carried out by the Operating System. In case of Linux it seems the data is written to the page cache until it can be written to the disk.What is ActiveMQ used for?
Apache Active Message Queuing (ActiveMQ) ActiveMQ is an open source protocol developed by Apache which functions as an implementation of message-oriented middleware (MOM). Its basic function is to send messages between different applications, but includes additional features like STOMP, JMS, and OpenWire.What is offset in Kafka?
The offset is a simple integer number that is used by Kafka to maintain the current position of a consumer. That's it. The current offset is a pointer to the last record that Kafka has already sent to a consumer in the most recent poll. So, the consumer doesn't get the same record twice because of the current offset.Is Kafka a message broker?
Kafka is a message bus developed for high-ingress data replay and streams. Kafka is a durable message broker that enables applications to process, persist and re-process streamed data. Kafka has a straightforward routing approach that uses a routing key to send messages to a topic.Is AWS Kinesis Kafka?
Amazon Kinesis. Like Apache Kafka, Amazon Kinesis is also a publish and subscribe messaging solution, however, it is offered as a managed service in the AWS cloud, and unlike Kafka cannot be run on-premise. Similar to partitions in Kafka, Kinesis breaks the data streams across Shards.Is Kafka free?
Kafka itself is completely free and open source. Confluent is the for profit company by the creators of Kafka. The Confluent Platform is Kafka plus various extras such as the schema registry and database connectors.