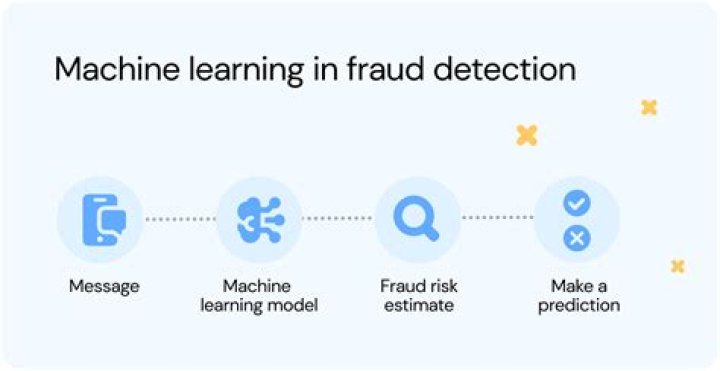
Anomaly detection (or outlier detection) is the identification of rare items, events or observations which raise suspicions by differing significantly from the majority of the data..
Regarding this, what is outlier in machine learning?
Machine Learning | Outlier. An outlier is an object that deviates significantly from the rest of the objects. They can be caused by measurement or execution error. The analysis of outlier data is referred to as outlier analysis or outlier mining.
Additionally, what are outlier detection methods? Some of the most popular methods for outlier detection are: Z-Score or Extreme Value Analysis (parametric) Probabilistic and Statistical Modeling (parametric) Linear Regression Models (PCA, LMS) Proximity Based Models (non-parametric)
Subsequently, one may also ask, what is anomaly detection in machine learning?
Machine learning for anomaly detection. In data mining, anomaly detection is referred to the identification of items or events that do not conform to an expected pattern or to other items present in a dataset. Machine learning algorithms have the ability to learn from data and make predictions based on that data.
How do you find outliers in data?
The IQR defines the middle 50% of the data, or the body of the data. The IQR can be used to identify outliers by defining limits on the sample values that are a factor k of the IQR below the 25th percentile or above the 75th percentile. The common value for the factor k is the value 1.5.
Related Question Answers
What are outliers in ML?
Outliers are extreme values that deviate from other observations on data , they may indicate a variability in a measurement, experimental errors or a novelty. In other words, an outlier is an observation that diverges from an overall pattern on a sample.What are the different types of outliers?
The three different types of outliers - Type 1: Global Outliers (also called “Point Anomalies”):
- Global Anomaly:
- Type 2: Contextual (Conditional) Outliers:
- Contextual Anomaly: Values are not outside the normal global range, but are abnormal compared to the seasonal pattern.
- Type 3: Collective Outliers:
Should outliers be removed?
Given the problems they can cause, you might think that it's best to remove them from your data. But, that's not always the case. Removing outliers is legitimate only for specific reasons. Consequently, excluding outliers can cause your results to become statistically significant.How do you classify outliers?
Outliers are identified by assessing whether or not they fall within a set of numerical boundaries called "inner fences" and "outer fences". A point that falls outside the data set's inner fences is classified as a minor outlier, while one that falls outside the outer fences is classified as a major outlier.Is XGBoost robust to outliers?
XGBoost (Extreme Gradient Boosting) or Elastic Net More Robust to Outliers. I am exploring XGBoost because of its predictive capabilities, the summary of feature importance it provides, its ability to capture non-linear interactions and also because I believe that it might be more robust in the presence of outliers.How do you treat outliers?
An
outlier is any data point that is distinctly different from the rest of your data points.
- Cap your outliers data. Another way to handle true outliers is to cap them.
- Assign a new value. If an outlier seems to be due to a mistake in your data, you try imputing a value.
- Try a transformation.
How do you manage outliers?
Here are four approaches: - Drop the outlier records. In the case of Bill Gates, or another true outlier, sometimes it's best to completely remove that record from your dataset to keep that person or event from skewing your analysis.
- Cap your outliers data.
- Assign a new value.
- Try a transformation.
Is anomaly detection machine learning?
Machine Learning for Anomaly Detection. Anomaly Detection is the technique of identifying rare events or observations which can raise suspicions by being statistically different from the rest of the observations.What are anomaly detection methods?
Anomaly Detection Techniques The simplest approach to identifying irregularities in data is to flag the data points that deviate from common statistical properties of a distribution, including mean, median, mode, and quantiles.Is Regression a machine learning?
Linear Regression is a machine learning algorithm based on supervised learning. Linear regression performs the task to predict a dependent variable value (y) based on a given independent variable (x). So, this regression technique finds out a linear relationship between x (input) and y(output).What is an example of an anomaly?
The definition of an anomaly is a person or thing that has an abnormality or strays from common rules or methods. A person born with two heads is an example of an anomaly. YourDictionary definition and usage example.What is anomaly detection used for?
Anomaly detection is applicable in a variety of domains, such as intrusion detection, fraud detection, fault detection, system health monitoring, event detection in sensor networks, and detecting ecosystem disturbances. It is often used in preprocessing to remove anomalous data from the dataset.What is the difference between outliers and anomalies?
Outlier = legitimate data point that's far away from the mean or median in a distribution. Anomaly detection refers to the problem of ending anomalies in data. While anomaly is a generally accepted term, other synonyms, such as outliers are often used in different application domains.How do you use anomaly detection?
Arbitrarily set outliers fraction as 1% based on trial and best guess. Fit the data to the CBLOF model and predict the results. Use threshold value to consider a data point is inlier or outlier. Use decision function to calculate the anomaly score for every point.Why anomaly detection is important?
A retailer must adopt anomaly detection as a way of life because it is effortless, easier, cheaper, better and faster. Anomaly detection is about identifying outliers in a time series data using mathematical models, correlating it various influencing factors and delivering insights to business decision makers.Is anomaly detection supervised or unsupervised?
Is Anomaly Detection Supervised or Un-supervised? Anomaly detection, also known as outlier detection is the process of identifying extreme points or observations that are significantly deviating from the remaining data. Whereas in unsupervised learning, no labels are presented for data to train upon.How do you analyze outliers?
The easiest way to detect outliers is to create a graph. Plots such as Box plots, Scatterplots and Histograms can help to detect outliers. Alternatively, we can use mean and standard deviation to list out the outliers. Interquartile Range and Quartiles can also be used to detect outliers.How do you identify multivariate outliers?
Multivariate outliers can be identified with the use of Mahalanobis distance, which is the distance of a data point from the calculated centroid of the other cases where the centroid is calculated as the intersection of the mean of the variables being assessed.What is the difference between univariate and multivariate outliers?
Univariate and Multivariate Outliers. A univariate outlier is a data point that consists of an extreme value on one variable. A multivariate outlier is a combination of unusual scores on at least two variables. Both types of outliers can influence the outcome of statistical analyses.